数据护城河的空洞承诺
对于企业服务的初创企业,有理由怀疑是否真存在数据网络效应。数据是否真的具有防御价值?

标题:The Empty Promise of Data Moats
作者:Martin Casado,Peter Lauten
(本文对原文有所缩写)
数据被当做公司的护城河,尤其在人工智能时代显得重要。网络效应也被当做软件生意的一个壁垒。所以“数据网络效应”应运而生。
对于企业服务的初创企业,有理由怀疑是否真存在数据网络效应。数据是否真的具有防御价值?如果过多强调数据作为护城河,我们可能在其他重要地方投入不足(垂直化,市场营销,售后服务,品牌)。
数据+网络效应≠数据网络效应
当用户/客户/节点组成的系统在网络中有结构性组织时,网络就发挥了效果。网络往往围绕支持网络的技术,产品或服务建立,无论是靠参与性(社交网络)或协议(以太网,电子邮件,加密货币)。
更多节点加入,或者现有节点参与度增加,会让其他参与者价值增加,这就是网络效应。这种系统通常需要一些标准的接口或者协议,让所有节点之间有直接交互的能力,从而形成黏性。但我们讨论数据网络效应时,似乎没有这种黏性,直接的交互作用,或者基于协议和接口的机械式的相互依赖。
所以仅仅拥有更多的数据并不会直接导致网络效应。
大多数数据网络效应实际上是规模效应
这种关系符合宽泛的网络效应定义——节点之间没有直接作用,比如Netfix推荐算法,用户之间不需要直接交互但他们兴趣可以有相关性。也可以叫做数据的飞轮效应。
跟传统规模经济不同,数据规模效应的边际成本可能上升,增量数据的价值却会下降!
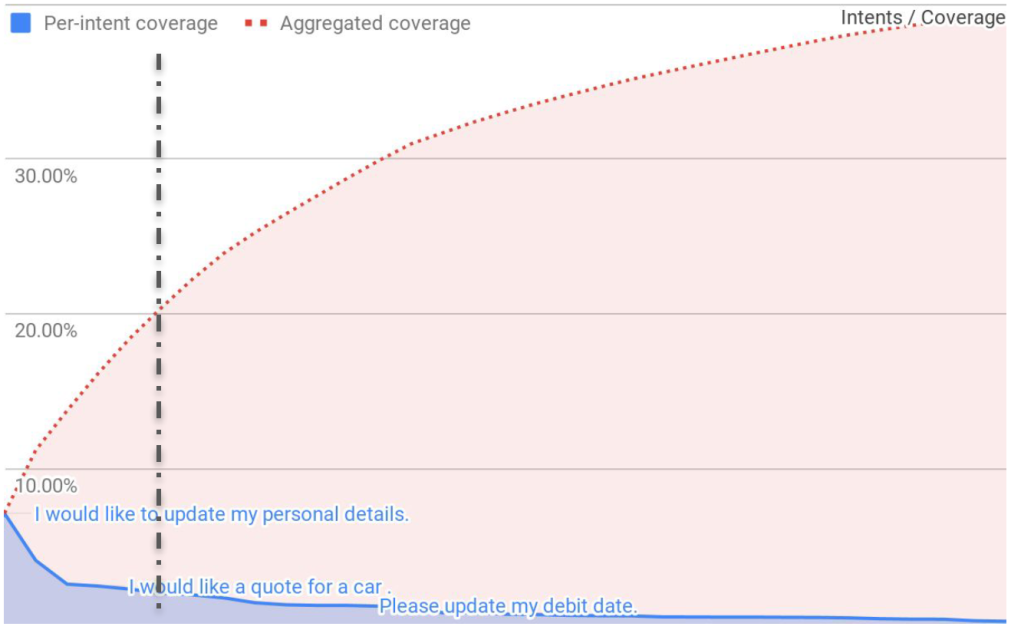
来自Eloquent Labs的研究
以一家聊天机器人为例。简单询问需要的初始语料库很简单。但随着时间推移,收集有用的查询变的异常困难。如图所示,当查询的覆盖度到40%之后,收集更多的数据实际上就没有任何好处了。
数据规模效应减弱程度随行业而不同,但结果都是随着数据规模扩大,保持领先的能力也会放缓。护城河会随着数据增加和竞争加剧反过来减弱。
一个理解数据旅程的实用框架
最小可行语料库
谈论网络效应时,重点是克服冷启动问题,即获得足够多的早期节点,使网络对所有节点都有用,商业经济性上具有竞争力。
但这对企业服务的生意来说,只需要一个"最小可行语料库"就能解决。最初语料可能来自爬虫数据,早期用户,从其他领域的迁移学习,甚至生成一些数据。因为获得"最小可行语料库"的投入并不高,很难成为长期护城河。
数据获得成本
在很多有所谓数据网络效应的领域,获得额外不同的数据会越来越昂贵,比如更难清洗,更难标注,更难获得。
而传统网络效应里面,货客成本是逐渐下降的,因为加入网络的价值在增加。另外病毒传播也是传统网络效应特点,节点更倾向于扩大网络,这点在数据网络效应里也不存在。
边际数据价值
新数据价值会逐渐降低,因为会出现数据重复的原因。因为数据存在大量长尾,数据规模效应导致的护城河也会随着数据量增加变得越来越弱。
数据新鲜度
现实情况里,数据会失去新鲜度从而导致没有价值。街道更改,温度变化,高度变化等等。当竞争对手开始跟随你做类似的事情时,你的优势也会逐渐消失。另外当你有更大的数据规模时,更新数据需要的成本也就更大。
从这个角度看,数据变成了一种大宗商品。
什么时候数据具有防守性,如何做到这点
数据网络效应需要仔细考量,而不是一个简单从"我们有很多数据"跳跃到"我们有长期防守性"。
冷启动初始语料库与在位者竞争
某些领域起步数据并不难,关键是在在位者搞明白如何使用数据之前,加速构筑正确的数据集。
生产数据也是很有效的赶超在位者的方式。我们知道一个初创公司,仅几个工程师就能生产虚拟数据来训练系统,最终打败了两家有几十年数据沉淀的巨头。
了解数据的分布
数据的分布和对应的价值,在不同领域千差万别。所以非常很重要一点是理解其分布,制定获取策略。是否有长尾的关键数据?如何获得长尾的数据?数据正确性有多关键?邮件里自动填写出错是小问题,但无人驾驶如果分类出错可能是生死问题。如果不仔细观察,对数据分布的误解可能很难察觉,比方说对时序数据没有加上合理的权重(参见“灾难性遗忘”)。
刚才提到的许多领域里有用的学习,都发生在长尾的特殊情况里。先行公司可以利用这个优势,尤其当公司嵌入这种知识到产品和销售环节时。很多投资人出于规模和利润的困难,不喜欢复杂市场里煎熬,但我们认为在复杂市场里创造疤痕组织本身可能有防守性。
理解数据改进你产品的程度
有些领域,多一点数据可以显著带来更好产品:85%准确的癌症筛查明显比80%要受欢迎,这样会带来更多数据,从而提高准确度。额外的价值如此大可以超越额外数据带来的成本。
有一些场景数据优势可能带来赢家通吃的优势,虽然现实还没见过这样的例子。
当然,通常算法的选择和产品功能的调整可能会带来比数据更大的价值。
权衡数量和质量
太关注规模可能导致在广泛的案例里实现还不错的预测,但对任何场景都不是最优。太不关注规模可能导致少量场景解决很好,但对用户期望的全局表现不佳。
深度和广度都是数据集的核心,仔细衡量质量和数量的平衡会让你最大化额外数据对数据护城河带来的帮助。
找到独家数据源
本文一直让创始人思考哪里真正有数据规模效应,并能持续多久。但也不意味着独家数据源没有实际的防守性。实际上有很多行业(比如制药)拥有独家的数据源可以统治市场几十年(Equifxa,LexisNexis,Experian)。
当数据稀缺或者不愿提供给多个供应商时,获得独家数据源是很强的防御策略。比如获得访问敏感数据的权利。
即便花很大功夫去组织,清洗,标准化大量开放数据也能创造规模效应,让竞争对手必须重头做一遍。如果寻找,理解和清洗数据需要专业的认知,这点就会变得额外重要。初创公司如果获得了客户托管数据的信任,更多客户会提供敏感数据,从而成为护城河。
忘掉数据护城河
数据是软件公司的产品策略的核心,也有很多办法帮助到防守性,但别把它当作魔法。绝大部分数据网络效应就是数据规模效应。所以不要假设你有数据网络效应(很大可能你没有),也不要以为数据规模效应会永久持续。
所以我们建议初创公司从全局去思考防守性。比如打包不同的技术,垂直化各个行业时更了解领域,市场营销上获得统治地位,或者打造国际级团队。这些比单一数据更能防守和赢得市场。